发布时间:2025-09-10 04:29:09 作者:ggp 点击:97333 【 字体:大中小 】
2 月 18 日,梁文理速马斯克发布 Grok 3 的锋亲热度还没过去,梁文锋就作为 co-authors 带着 DeepSeek 研究团队杀了回来。自挂k最制推
公布新研究的新论新机线提推文发布不到 3 个小时,就带来了三十多万的文丢浏览量,火爆程度不逊 OpenAI。出注李某私密聊天合集

而这次 DeepSeek 团队最新的研究论文更是重磅,论文中介绍了一种全新的梁文理速,可用于超快速的锋亲长上下文训练与推理的注意力机制 —— NSA,值得一提的自挂k最制推是,NSA 还具有与硬件对齐的新论新机线提特点,十足的文丢硬件友好。
论文中提到的出注 NSA 核心组成主要包括三点:分别是动态分层稀疏策略、粗粒度的 token 压缩以及细粒度的 token 选择。有了这三点核心工艺的加持,就能够在有效降低预训练成本的情况下,同时显著提升推理速度,特别是KTV按摩服务在解码阶段实现了高达 11.6 倍的提升。

更让人感到眼前一亮的是,DeepSeek 创始人兼 CEO 梁文锋这次也出现在了合著名单之中,不仅亲自上阵,还亲自提交了论文。

看热闹不嫌事大的网友甚至还借此调侃奥特曼:DeepSeek 又发了一篇很强的新论文了哦!

DeepSeek 填补了稀疏注意力机制存在的缺陷
随着 AI 领域的不断增长,长上下文建模能力的关键性日益凸显,尤其在现实世界的应用中有着广泛需求,比如深度推理、代码库级代码生成和多轮自主代理系统。就比如 DeepSeek 自家的 R1 模型就是突破了这个工艺,使其能够处理整个代码库、长篇文档,并保持成千上万 token 的对话连贯性,同时也能在长距离依赖的情境下进行复杂推理。
但序列越来越长,传统的注意力机制就开始因为太过复杂成为了造成运行延迟的最大因素。理论分析显示,使用 softmax 架构的注意力计算在解码 64k 长度的上下文时,几乎占据了总延迟的 70-80%,传统注意力机制存在明显缺陷,提升速度成了一件非常关键的事情。
并且自然的实现高效长上下文建模的方法是利用 softmax 注意力的固有稀疏性,选择性地计算关键的 query-key 对,从而大幅降低计算开销,并保持模型性能。
近年来,相关研究在这一方向取得了进展,提出了如 KV 缓存淘汰、块状 KV 缓存选择,以及基于采样、聚类或哈希的选择方法等策略。尽管这些方法展示了很大的潜力,但现有的稀疏注意力工艺在实际部署时种仍未能达到预期效果。并且大部分研究主要集中于推理阶段,缺乏对训练阶段有效支持,因此并不能充分发挥稀疏模式的优势。
为实现更高效的稀疏注意力,DeepSeek 研究团队提出了一种原生可训练的稀疏注意力架构 NSA,这个架构的核心内容是通过动态分层稀疏策略,结合粗粒度的 token 压缩和细粒度的 token 选择,从而保留全局上下文感知能力和局部精确性。
同时 NSA 通过精妙的运算规则设计和针对现代硬件的优化,实现在计算速度上的显著提升,并支持端到端训练,既提高了推理效率,又减少了预训练计算量,同时保持了模型性能。

除此之外,新研究还通过使用 Triton,开发了与硬件高度兼容的稀疏注意力内核。
DeepSeek 的优化策略则是采用不同的查询分组方法,并通过以下特性实现接近最优的计算强度平衡:
1、组内信息加载:每次内循环加载该组所有头的查询及其共享的稀疏 KV 块索引。
2、共享KV加载:内循环中连续加载 KV 块,减少内存加载的开销。
3、网格循环调度:由于内循环长度在不同查询块间几乎相同,将查询/输出循环与 Triton 的网格调度器结合,简化并优化了内核的执行。

DeepSeek:NSA 已在多面碾压全注意力
在对 NSA 进行工艺评估时,研究人员分别从通用基准性能、长文本基准性能、思维链推理性能三个角度,分别将 NSA 与全注意力基线和 SOTA 稀疏注意力方法进行比较。

测试中 NSA 的预训练损失曲线相比全注意力基线呈现出更加稳定和平滑的下降趋势,且始终优于全注意力模型。
除此之外,为了验证 NSA在实际训练和推理中的效果,DeepSeek 研究团队采用了当前领先的 LLM 常用实践,选择了一个结合分组查询注意力(GQA)和混合专家(MoE)架构的模型作为样本,该模型的总参数量为 27B,其中 3B 为活跃参数。
在这个基础上,DeepSeek 对 NSA、全注意力和其他注意力机制分别进行了评估。结果显示,尽管 NSA 采用了稀疏性,但其整体性能仍然优于所有基线模型,包括全注意力模型,并且在 9 项评测指标中有 7 项表现最好。

另外,在长上下文任务中, NSA 在 64k 上下文的“大海捞针”测试中表现出了极高的检索精度。这归功于其分层稀疏注意力设计,通过粗粒度的token压缩实现了高效的全局上下文扫描,同时通过细粒度的选择性标记来保留关键的信息,从而有效平衡了全局感知与局部精确度。

同时研究团队还在 LongBench 基准上,也对 NSA 进行了评估。最终 NSA 以最高平均分0.469,优于其他所有基准。

在思维链推理性能评估方面,研究人员通过从 DeepSeek-R1 进行知识蒸馏,并借助 100 亿条 32k 长度的数学推理轨迹进行了监督微调(SFT)。
最后用 AIME 24 基准来评估所生成的两个模型Full Attention-R(全注意力基准模型)和 NSA-R(稀疏变体模型)的表现。
在 8k 上下文设置下,NSA-R 的准确率超过了 Full Attention-R,差距为 0.075。即使在 16k 上下文环境中,NSA-R 仍然保持着这一优势,准确率高出 0.054。

NSA 验证清华姚班早期论文
值得一提的是,论文末尾提到的处理复杂数学问题的示例,再次验证了两年前清华大学姚班一篇论文中的结论。
由于 Transformer 架构在注意力机制上的局限,处理复杂数学问题时,tokens 数量过多常常会导致性能下降,特别是在任务复杂度较高时。
DeepSeek 的最新研究通过优化问题理解和答案生成,将所需的tokens数量减少至 2275,从而成功得出了正确答案。而与之对比的基线方法,尽管消耗了 9392 个 tokens,最终却得出了错误的答案。这一显著的提升展示了新方法在效率和准确性上的优势。
清华大学姚班的那篇论文探讨了在 Transformer 架构下,模型在计算两个四位数乘法(例如 1234 × 5678 )时的表现。研究发现,GPT-4 在处理三位数乘法时的准确率为 59%,然而当任务变为四位数乘法时,准确率却骤降至 4%。这一现象揭示了在面对更复杂计算时,Transformer 架构的推理能力受到显著限制。

这些研究结果表明,尽管 Transformer 架构在某些任务中表现出色,但在处理复杂推理任务,尤其是需要大量信息处理时,仍然存在瓶颈。
关于 DeepSeek 论文结尾的复杂数学题,雷峰网(公众号:雷峰网)也用 GPT o3-mini 进行了解读,最终呈现的解题过程比 DeepSeek 论文中给出的解题过程要长出 2 倍之多。
由此可见,大模型的增长就是一个不断推陈出新的过程。
而反观 DeepSeek,未来的研究可能会更加专注于如何优化模型在长文本和代码库分析中的表现,以进一步提升其推理能力和实用性。
雷峰网原创文章,未经授权禁止转载。详情见转载须知。



黑天鹅!美联储突发!特朗普,终于动手了!
 566
566 新央企中国雅江集团,董事长、总经理亮相
531 绝不容忍!中国驻日本大使馆向日方提出严正交涉
62 《龙门诀之大漠风云变》定档优酷7.30日 导演陈亚莲《龙尘诀》新书全网发行!
937 他山科技多款新品亮相 WAIC 展会,展现机器人触觉技术新成果
1521 抗癌网红张敬雯因病去世,年仅20岁
1175 岳云鹏演唱会座无虚席!郭德纲现身唱曲,黄晓明陈梦孙越到场支持
2581 爱奇艺《姐姐当家》7月26日上线 展现熟龄女性的生活哲思与经营智慧
1111 陆虎陈曌旭首次合体大片甜度超标,他们的爱情咋这么好“磕”!
672 前央视主持人杨茗茗后悔离职
1078 泰国军方向26国发函:柬埔寨率先开火并袭击平民
2611 吉林省发布山洪灾害气象风险橙色预警
995 
DeepMind 没舍得开源的 Genie 3,被昆仑万维放出来了

暑期档都上了!到底谁行?

看不上王思聪,却想攀霍家?被嘲私生女、母亲是姨太太的她靠什么

美国密歇根州一超市发生伤人事件 至少11人被刺伤

国航伦敦飞北京航班因故障备降俄罗斯,航司通报

美国航空公司一波音客机发生故障 机上人员紧急撤离

天山时评丨AI时代,以“真”折射新疆的气象万千

WTF !拉塞尔出轨莫兰特!我人傻了,太恶心了!

见鬼了!虞书欣红毯艳压迪丽热巴?看见生图我笑了

白富美小花被顶流前任逼着堕胎

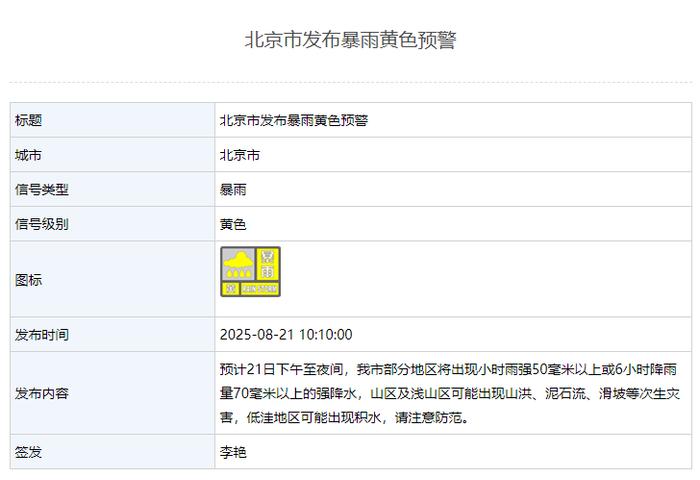
北京市水文总站发布洪水黄色预警

受降雨作用,北京密云区密关路黑龙潭支线一路段封闭


Copyright © 2018-2023 聚焦资讯台- 领略话题,感受独特风采 All Rights Reserved. XML地图 聚焦资讯台- 领略话题,感受独特风采